CMS Physics Objects 2011
Introduction to “physics objects”
Particle colliders are the most powerful tools we have to study the building blocks of our Universe and the laws governing them. Gigantic detectors, such as CMS, act as cameras that take "photographs" of the particle collisions, allowing us to test our understanding of Nature.
Although we cannot observe the particles created in the collisions themselves, their decay products leave signals in the CMS sub-detectors. Dedicated software then uses these signals to "reconstruct" the decay products, which we classify into families called "physics objects" (see list below). It is important to note that these reconstructed physics objects are only interpretations of the signals observed by CMS and as such are subject to various sources of uncertainty (efficiencies, misidentifications etc.).
For example, see the two events below, both belonging to a collection of muons. The first shows hits in the muon chamber segments but does not in fact contain a real muon. The second event, on the other hand, shows a clear muon flying through CMS.

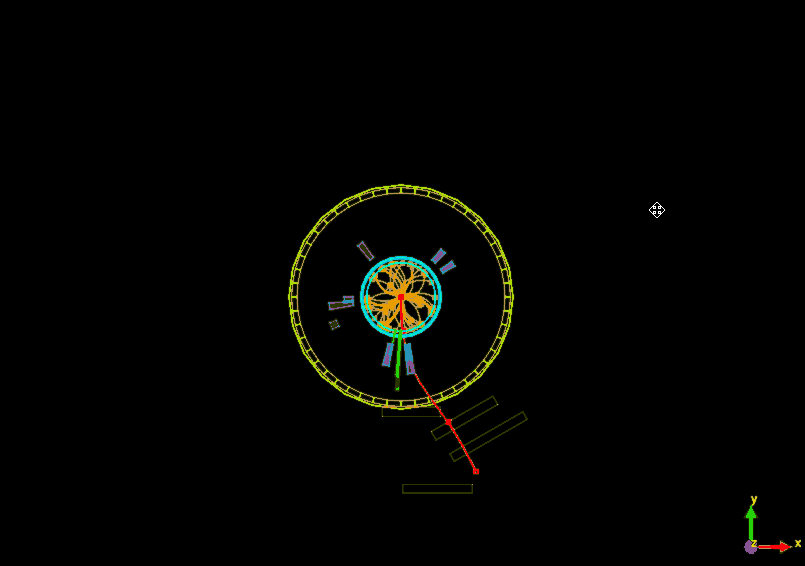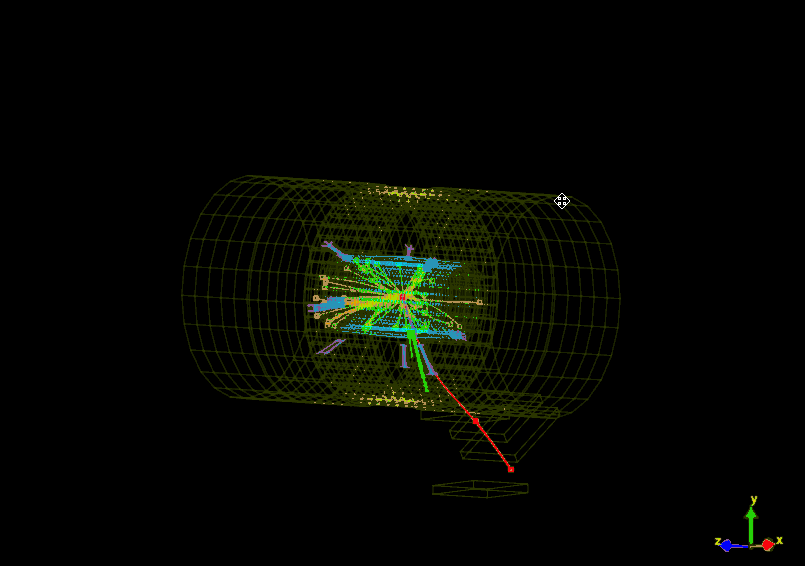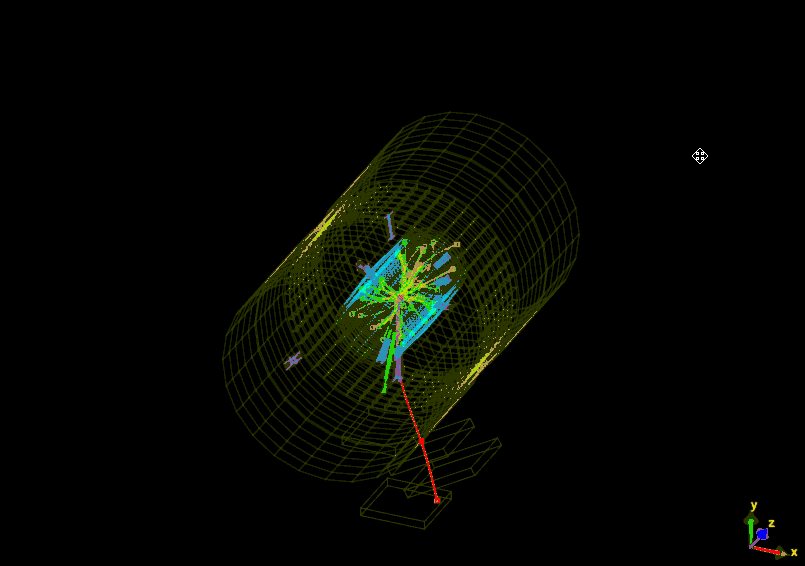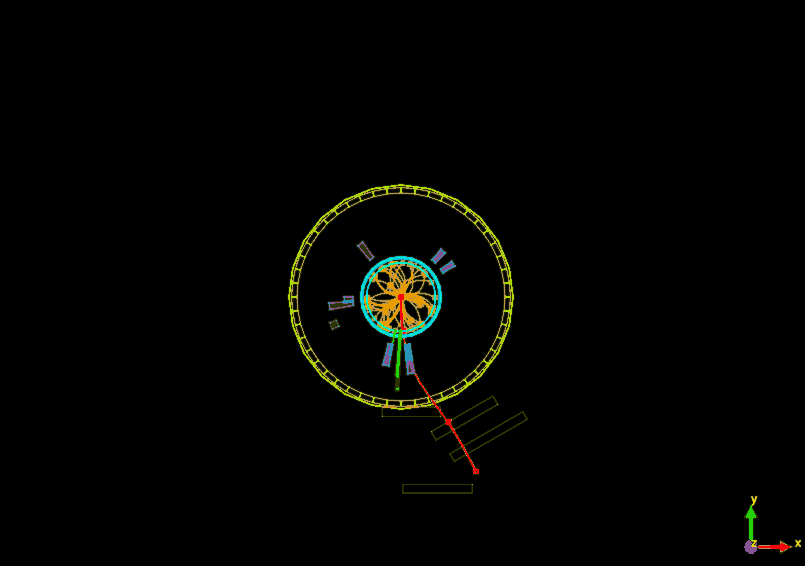
Like assembling a jigsaw puzzle, we have to put together all the individual information about the physics objects from each collision to get a picture of what took place at the collision point. Analysing several (trillions!) of collisions allow us to look for patterns in the data that may correspond to previously undiscovered particles or phenomena, or allow us to make even more precise measurements of known phenomena.
Standard collections of physics objects can be used for the vast majority of CMS analyses without further tweaking. However, different analyses may require different combinations of physics objects and information about how they are related. The trick is to balance efficiency of data selection (select as many objects of a particular type) versus the fake rate (probability of misidentification).
Below, you will find the collections for the CMS physics objects in the AOD files — electrons, photons, muons, jets (and a special subset, b-jets) and missing transverse energy (MET) — along with information on how to perform some simple analyses using these. With this knowledge and the example we provide, you should be able to select the objects and collections suitable for the analyses you intend to perform.
A note about Particle Flow: The particle-flow algorithm aims at reconstructing and identifying all stable particles in the event, i.e., electrons, muons, photons, charged hadrons and neutral hadrons, with a thorough combination of all CMS sub-detectors towards an optimal determination of their direction, energy and type. This list of individual particles is then used, as if it came from a Monte-Carlo event generator, to build jets (from which the quark and gluon energies and directions are inferred), to determine the missing transverse energy (which gives an estimate of the direction and energy of the neutrinos and other invisible particles), to reconstruct and identify taus from their decay products and more. To learn more about it, it would be good to start with the public note CMS-PAS-PFT-09-001, which explains the concepts. You can also check CMS-PAS-PFT-10-001, CMS-PAS-PFT-10-002 and CMS-PAS-PFT-10-003 for information regarding the commissioning done in 2010, although these notes are less adapted for general use.
List of CMS physics objects
Electrons 
The collection most commonly used in 2011 data was recoGsfElectrons_gsfElectrons__RECO (collection of objects type reco::GsfElectron).
Energy and momentum were "ready-to-use". However an additional selection was needed for identification. The cuts can be found here, with information on how to access the variables and the value to be applied for different selections.
It is important to apply identification and isolation selection to avoid large background contamination.
Photons 
The collection most commonly used in 2011 data was recoPhotons_photons__RECO (collection of objects type reco::Photon).
The energy and momentum were ready to use. However for photon identification additional selection needs to be applied. These cuts are listed in Table 1 here [PDF].
Converted photons are included in the above mentioned collection. The conversion seeded by the ECAL clusters were already attached to the photon collection and can be accessed with this information.
Difference between "AllConversions" and "conversions": "AllConversions" are conversion seeded with tracking properties, while "conversions" are seeding by the ECAL clusters. The latter are very similar to the conversion also linked to the photon, it slightly differs for pT cuts.
The default collection of photons has a very very loose pre-selection. Basically every energy deposit in the ECAL with ET > 10 GeV and HCAL energy / ECAL energy < 0.5 is reconstructed as a photon. This means that without any additional selection the background is very very large and it is not usable for any analysis.
Muons 
The muons most commonly used in 2011 data analysis are contained in the collection recoMuons_muon__RECO.
This includes muons identified by the Particle-Flow algorithm as well.
Most of the muon properties (e.g. momentum and isolation variables) are available in the reco::Muon object collection, ready to use. Some precaution in the choice of the momentum or isolation definition may be needed, depending on the analysis (see below). Some additional corrections to the muon momentum (in general very small, < 1%) can be applied, and are especially recommended for precision measurements. These are provided centrally by the muon POG and are to be applied on top of the momentum stored in the reco::Muon object. In general, the objects in the reco::Muon collection cannot be used "out of the box", but some further selections are necessary. The most widely used IDs are documented in CMS-DP-2014-020.
Things to remember
-
The
reco::Muoncollection includes muons reconstructed by different algorithms: fit in the muon chambers alone (standalone muons), fit in the Tracker alone + matching with muon hits (Tracker muons), and combined fit of Tracker and muon hits (global muons). Not all the objects included in this collection are suitable for every analysis: e.g. it contains non-prompt muons from hadron decays or fake muons produced by random matching of hadron tracks with muon-chamber hits. Therefore further selections and identification criteria must be applied to reject fake or background muons. Five main selections are recommended for 2011 data analysis:- the Soft Muon selection, optimised for low-pT muons (pT < ~10 GeV/c) and used in B-physics and Quarkonia analyses;
- the Loose Muon selection, useful for analyses with multi-lepton final states where high efficiency on muons is important (H→ZZ→4l analysis, for example);
- the Tight Muon selection, most effective in rejecting non-prompt muons from decays and used in many CMS analyses (e.g. those involving muons from W and Z);
- the high-pT selection, similar to the Tight one, but imposing additional requirements on the quality of the measured momentum;
- the Particle-Flow Muon selection, which is required by the Tight and Loose identifications and which uses information from all sub-detectors to select with high efficiency isolated and non-isolated muons, while rejecting fake muons from hadron mis-identification, giving the best overall performance. An exact definition of the selections to be used for 2011 data analysis can be found in CMS-DP-2014-020.
-
The
reco::Muonobject is recommended for all analyses involving muons with low and intermediate pT (pT < ~200 GeV/c): for pT < 200 GeV, this corresponds to the momentum obtained from the fit of the Tracker hits only; for pT > 200 GeV/c, the default momentum is chosen between the results of the Tracker-only fit and the combined fit of Tracker and muon-chamber hits, based on the quality of the two fits. For analyses involving very-high-pT muons, subject to possible energy loss by bremsstrahlung, dedicated refits of the global-muon track are available: the Tracker-Plus-First-Muon-Station (TPFMS) fit, which uses the Tracker and first muon-station hits; and the Picky fit, which uses hits from the Tracker and from all the muon chambers, but selecting the muon hits with tight compatibility criteria in chambers with high hit occupancy (i.e. with possible showers). The recommended choice to optimise the momentum resolution at high pT is provided by the "Tune P" algorithm, which selects the momentum obtained from the best of three different fits: the Tracker-only, the TPFMS and the Picky fit. At times, the Particle-Flow algorithm can prefer the momentum information coming from a fit other than the inner track or the Tune-P decision. In topologies such as W/Z signals, and below 200 GeV of momentum, differences between the recommended decision and Partcle-Flow are well below 0.5%. Care should be taken in analyses relying heavily on Particle-Flow and investigating topologies very different from the ones mentioned above. -
The isolation variables, i.e. energy or momentum deposits in cones centred around the muon track, are stored in the
reco::Muonobject, and can be used to compute different isolation definitions. The recommended ones for 2011 data analysis are the following:- Tracker relative isolation: scalar sum of the pT of all Tracker tracks reconstructed in a cone of radius centred on the muon track direction;
- combined relative PF isolation mitigated against pile-up using method: sum of the p
T of all PF charged hadrons coming from the primary vertex + max(sum pT of neutral hadrons and photons − 0.5 x sum pT of charged hadrons coming from pile-up vertices, 0). The recommended cone radius to be used to compute all the above, in case of PF isolation is .
Jets and missing transverse energy (MET) 
(N.B.: b-jets described separately below)
The most commonly used variants of jets and missing ET are:
recoPFJets_ak5PFJets__RECO(collection of objects of typereco::PFJet)recoPFMETs_pfMet__RECO(collection of objects of typereco::PFMET)
The jets typically require Jet Energy Correction (JEC) to be applied, and the preference for MET is to apply so-called type-I corrections, which propagate the JEC to MET. The jets should have a JEC stored, although this is often re-run for analysis with the latest version of JEC constants. The 2011 AOD should have a reasonable JEC, although there may have been slight changes to JEC in later re-reco versions that we have not propagated all the way.
For most educational purposes, the PF jets and MET are ready to use after JEC and type-I, since the corrections are relatively small (typically < 5% and mostly < 10%) and the changes in the corrections would have been even smaller (typically < 2% level). The jets are validated for corrected pT>10 GeV and |η|<4.7 (this is used in type-I MET), but for most physics analyses we recommend corrected pT>30 GeV and |η|<2.5, where the jet reconstruction and calibrations are the most reliable.
Jets — Things to remember
- JEC: jets should be corrected for JEC, the knowledge of which is the dominant jet systematic; the JEC uncertainties may also be available in AOD
- JetID: jet quality cuts should be used to avoid detector problems; there should be tight and loose flags for this
- JER: jet results should be unfolded for jet pT resolution (JER), which varies between 5–15%; if there is an accompanying MC sample, the MC JER should be oversmeared typically by 10% or more with similar uncertainty; if not, it would be useful to provide parameterised JER
MET — Things to remember
- Quality flags: MET should be cleaned for detector problems; there should be several flags for these
- Type-I: whether or not JEC is propagated to MET, the JEC is an important systematic
- Important uncertainties are JER, JES and unclustered energy: the JER resmearing (uncertainty on JER per jet: 5–20%) and JES systematics should be propagated to MET, and unclustered energy should be considered as an extra systematic by scaling it up and down by 10%.
- For SUSY-type analysis, MET tails often come from jets (ECAL holes, heavy flavour, JER), so analyses typically apply cuts on (jet, MET) to ensure MET is not aligned with one of the jets
b-jets 
The most commonly used tags in 2011 analyses were the Track Counting High Purity (collection: trackCountingHighPurBJetTags) and Track Counting High Efficiency (collection: trackCountingHighEffBJetTags).
Also in use were the Simple Secondary Vertex High Efficiency (collection: simpleSecondaryVertexHighEffBJetTags) and Simple Secondary Vertex High Purity (collection: simpleSecondaryVertexHighEffBJetTags).
Finally, later analyses on 2011 data have used the Combined Secondary Vertex (collection: combinedSecondaryVertexBJetTags) and maybe the Jet Probability (collection: jetProbabilityBJetTags) algorithms.
The collections contain the discriminator values for each jets, for the respective b-tagging algorithm. In order to decide if a jet is tagged, one has to ask the discriminator value to be greater of a specific threshold.
We define three possible thresholds (working points) for each algorithm, which correspond to the cuts on the discriminator that allow to reduce the rate of mis-identification of light jets as b-jets to 10% (loose working point), 1% (medium working point) and 0.1% (tight working point), respectively.
Monte Carlo simulation does not reproduce correctly the distributions of the b-tag discriminator observed in data. As a consequence, the efficiencies for a b-jet to be tagged (as well as the probability for a light jet to be mis-tagged) when applying a certain working point requirement is not well reproduced in MC. The BTV POG provides data-to-MC scale factors to correct the efficiencies of b-tagging (and the mis-tagging rates) predicted by the simulation.
Things to remember
- The values of the discriminator threshold defining each working point for the different b-tagging algorithm: this information is available here.
- The values of the data-to-MC scale factors.
- How to apply the scale factors to the simulated events: some examples are provided.
Taus 
The hadronic tau collection most commonly used in Run-1 data is recoPFTaus_hpsPFTauProducer__RECO (collection of objects type reco::PFTau).
The energy and momentum of the tau candidates are ready to use. However for full tau identification, a set of additional selections needs to be applied. The selections correspond with steps of reconstruction and identification of hadronic taus: decay-mode finding and discrimination against jets (isolation), electrons and muons. The selections are provided as tau discriminants (collections of objects type reco::PFTauDiscriminator). Please consult the full list of available discriminants and their usage.